
Ноя
Может ли в выдаче дублированный контент занять место оригинала?
 Дэн Петрович (Dan Petrovic), директор австралийской компании Dejan SEO, провел эксперимент и рассказал, как ему удалось показывать свою скопированную версию страниц выше оригинала в выдаче.
Дэн Петрович (Dan Petrovic), директор австралийской компании Dejan SEO, провел эксперимент и рассказал, как ему удалось показывать свою скопированную версию страниц выше оригинала в выдаче.
Например, он смог ввести в заблуждение Google при ранжировании страницы MarketBizz, которая отображалась на dejanseo.com.au вместо marketbizz.nl.
Как он это делал? Он просто копировал всю страницу, исходный код и все остальное и вставлял эту информацию на новый URL на своем сайте, связывал страницы и установил Google+1. Результат появился через несколько дней.
Он приводит скриншот поисковой выдачи Google для страницы, по команде info и также по запросу title страницы:
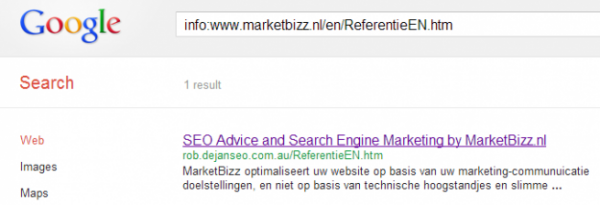
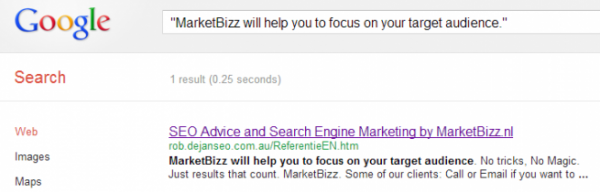
С различной степенью успешности он проделал то же самое с тремя другими доменами.
В некоторых случаях, использование атрибута rel=canonical предотвращало похищение результата полностью, но не во всех. Кроме того, похоже, что использование авторства может также помочь избежать «угона» результатов.
Дэн Петрович был в состоянии захватить даже первый результат в выдаче по запросу Рэнд Фишкин (с его согласия):
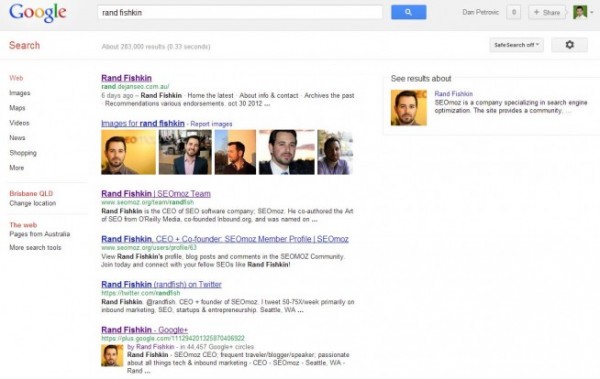
Единственное объяснение, тому, что эти уловки иногда срабатывают, это то, что фильтр Google Duplicate Content считает новый URL более важной страницей и заменяет ею оригинал.
Авторы эксперимента отправили письмо в Google с запросом объяснения результатов, однако Google его пока никак не комментирует.
Источник: seonews.ru
Поделиться в соц. сетях
Рекомендуем ещё
 (Еще не оценили)
(Еще не оценили)